引言
在接下来的文章中会主要介绍 ChaosBlade 基础资源类的故障场景以及底层实现原理,目前 ChaosBlade 已支持的基础资源类故障场景如下:
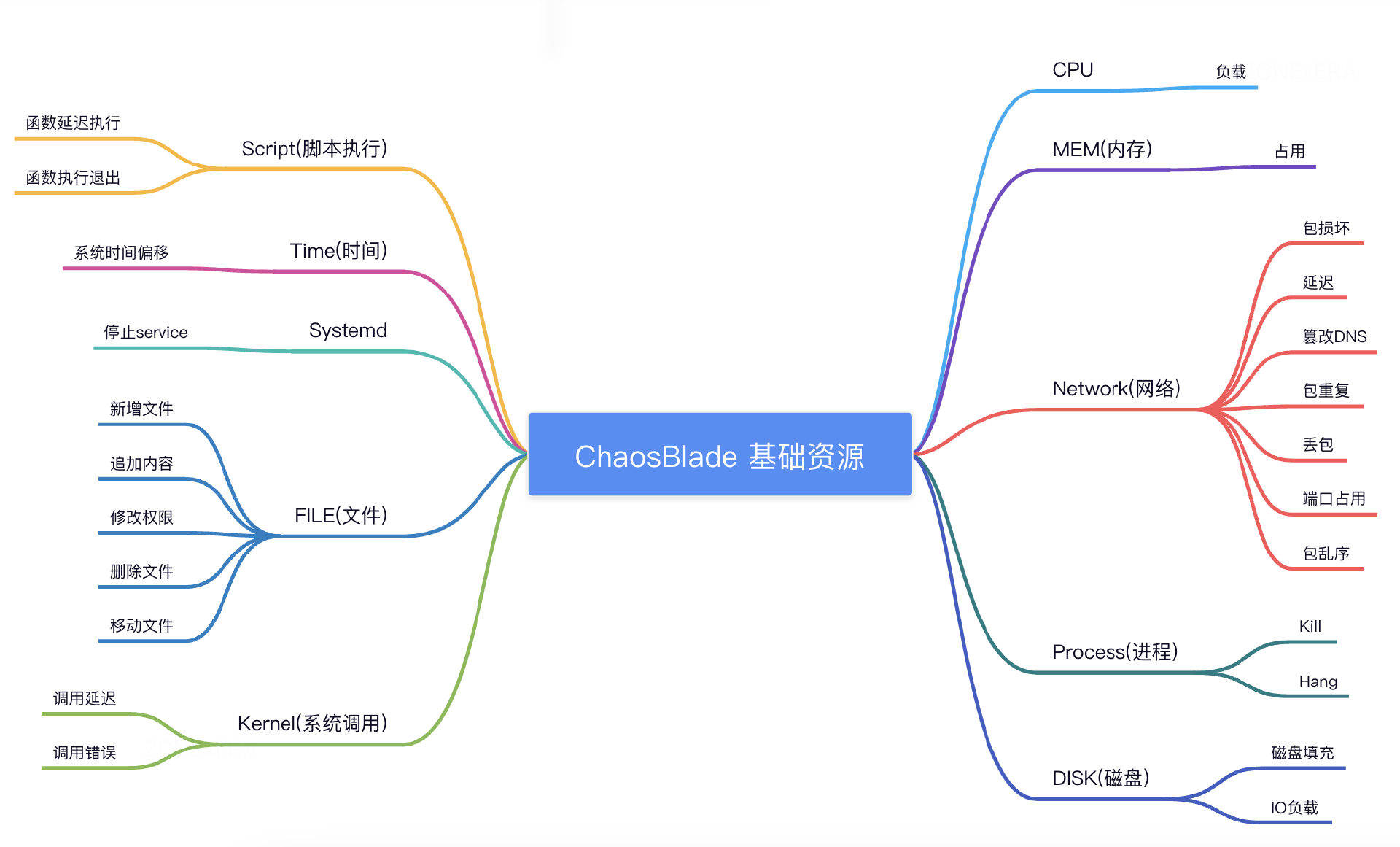
介绍
服务器的稳定性和性能优化对于保障业务的顺利运行至关重要。然而,服务器 CPU 负载的异常升高往往会导致服务响应时长增加、任务处理速度变慢甚至系统假死等问题。为了更好地了解系统性能,增强系统的稳定性,以及提高应对故障的能力,开发人员和系统管理员需要一种有效的方式来模拟 CPU 负载故障。而在这里,我们将引入 ChaosBlade,一个强大的工具,用于模拟故障并帮助用户实现 CPU 负载的升高
下面是一些 CPU 负载故障注入的验证场景:

通过本文我们将了解如何利用 ChaosBlade 实现 CPU 负载故障的模拟,同时会深入挖掘 ChaosBlade CPU 故障模拟的核心代码,了解其实现机制。项目地址: https://github.com/chaosblade-io/chaosblade-exec-os
粗暴实现
在介绍 ChaosBlade 模拟 CPU 故障的实现之前,我们先了解下最简单的实现:有多少核心就开启多少个协程/线程去跑 for 循环,例如在 golang 中可以按照如下方式打满 CPU 的使用率。
1func main() {
2 cpuCount := runtime.NumCPU()
3 for i := 0; i < cpuCount; i++ {
4 go func() {
5 for {
6 }
7 }()
8 }
9 select {}
10}
不过这样的模拟 CPU 负载实在过于简单粗暴,往往现实场景要比这个复杂的多,例如在多核(大于 1 个核心)CPU 机器中, 由于突然过来一波大流量/或者定时任务触发等各种原因,导致 CPU 使用率瞬时打满或阶梯式升高等,那么这种粗暴简单的实现明显不能满足于复杂的现实场景
ChaosBlade CPU 故障模拟
功能介绍
目前 ChaosBlade 支持 CPU 负载场景,包括
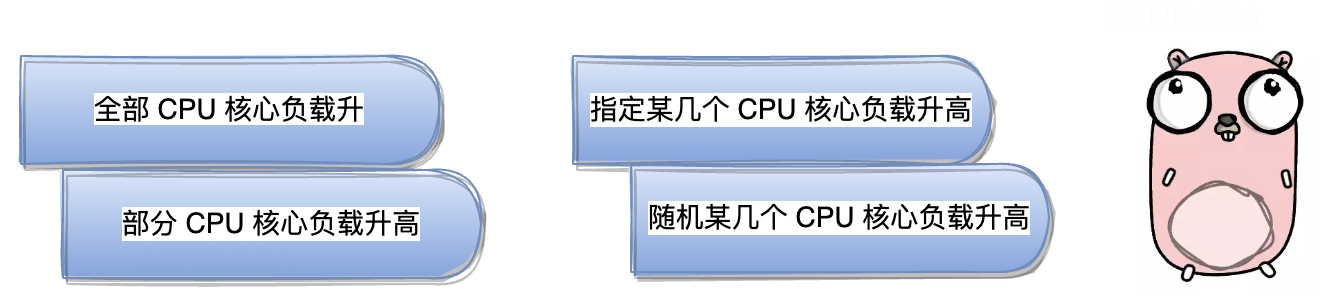
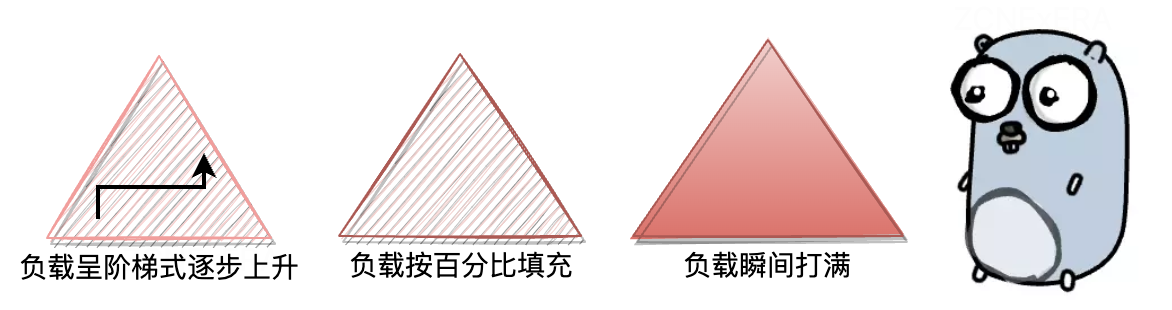
负载填充也分为几种方式:
安装与使用
首先可以下载 ChaosBlade Tool 工具包,下载地址 https://github.com/chaosblade-io/chaosblade/releases ,下载后解压到要注入故障的目标机器中执行命令即可。
命令格式:
1./blade create cpu load [flags]
2
3参数
4--timeout string 设定运行时长,单位是秒,通用参数
5--cpu-count string 指定 CPU 满载的个数
6--cpu-list string 指定 CPU 满载的具体核,核索引从 0 开始 (0-3 or 1,3)
7--cpu-percent string 指定 CPU 负载百分比,取值在 0-100
8--climb-time 指定 CPU 负载到目标值的时间
9--cgroup-root 指定 cgroup 路径,在容器环境中使用
使用案例:
1# 创建 CPU 满载实验
2blade create cpu load
3
4
5# 返回结果如下
6{"code":200,"success":true,"result":"beeaaf3a7007031d"}
7# code 的值等于 200 说明执行成功,其中 result 的值就是 uid。使用 top 命令验证实验效果
8Tasks: 100 total, 2 running, 98 sleeping, 0 stopped, 0 zombie
9%Cpu0 : 21.3 us, 78.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
10%Cpu1 : 20.9 us, 79.1 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
11%Cpu2 : 20.5 us, 79.5 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
12%Cpu3 : 20.9 us, 79.1 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
13
14
15# 4 核都满载,实验生效,销毁实验
16blade destroy beeaaf3a7007031d
17
18
19# 返回结果如下
20{"code":200,"success":true,"result":"command: cpu load --help false --debug false"}
21
22
23# 指定随机两个核满载
24blade create cpu load --cpu-count 2
25
26
27# 使用 top 命令验证结果如下,实验生效
28Tasks: 100 total, 2 running, 98 sleeping, 0 stopped, 0 zombie
29%Cpu0 : 17.9 us, 75.1 sy, 0.0 ni, 7.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
30%Cpu1 : 3.0 us, 6.7 sy, 0.0 ni, 90.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
31%Cpu2 : 0.7 us, 0.7 sy, 0.0 ni, 98.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
32%Cpu3 : 19.7 us, 80.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
核心源码解析
下面将通过核心代码,重点分析下 CPU 故障注入的实现原理,这里有几个关键点将会分别介绍
如何获取正确的 CPU 使用率
在实现 CPU 负载故障时,获取正确的 CPU 使用率是至关重要的,CPU 使用率是指在特定时间段内,CPU 执行非空闲状态任务的时间与总时间之比,通常以百分比表示。它反映了 CPU 在一段时间内的忙碌程度或负载情况。例如,如果在过去的一秒钟内,CPU 有 800 毫秒的时间是处于忙碌状态,那么 CPU 使用率就是 80%(800 毫秒除以总的 1000 毫秒,再乘以 100)
物理机
这里以 Linux 系统举例可以通过读取**/proc/stat** 文件,它提供了关于系统和 CPU 的各种统计信息。这些统计信息是实时更新的,可以用于监视系统性能和资源利用情况。
在大多数情况使用上面方式就可以正确获取到 CPU 使用率了,但是在容器环境中,如果读取**/proc/stat** 是获取的宿主机的 CPU 统计信息,而不是容器本身的,例如在容器中执行 top 命令时,获取的信息是宿主机(物理机)的信息,而不是容器内部的信息,因为top 命令访问的是容器进程在宿主机上的 /proc 目录,所以得到的信息是宿主机上的信息,那么我们如何在容器中获取正确的 CPU 使用率呢?
容器
容器技术(如 Docker)本身会在容器启动时使用 cgroup 来对容器的资源进行管理和隔离。想查看容器的 cgroup 配置,可以在宿主机上使用 ls 命令查看 **/sys/fs/cgroup/** 目录。在这个目录下,能够找到与容器相关的 cgroup 目录,其名称通常与容器的 ID 或名称相关联。进入容器的 cgroup 目录后,你将看到与容器资源相关的文件和子目录,如 cpu, memory, blkio 等,这些子目录用于配置和管理相应资源的限制。
在 ChaosBlade 中也是按照这两种不同环境分别获取的 CPU 使用率,获取物理机中的 CPU 使用率是直接使用开源库 gopsutil(底层实现也是读取/proc/stat 文件)
代码路径在 cpu/cpu_liunx.go#getUsed func:
1func getUsed(ctx context.Context, percpu bool, cpuIndex int) float64 {
2 pid := ctx.Value(channel.NSTargetFlagName)
3 cpuCount := ctx.Value("cpuCount").(int)
4 // 容器中获取 CPU 使用率
5 if pid != nil {
6 cgroupRoot = "/sys/fs/cgroup/"
7 cgroup, err := cgroups.Load(exec.Hierarchy(cgroupRoot.(string)), exec.PidPath(p))
8 stats, err := cgroup.Stat(cgroups.IgnoreNotExist)
9 pre := float64(stats.CPU.Usage.Total) / float64(time.Second)
10 time.Sleep(time.Second)
11 nextStats, err := cgroup.Stat(cgroups.IgnoreNotExist)
12 next := float64(nextStats.CPU.Usage.Total) / float64(time.Second)
13 return ((next - pre) * 100) / float64(cpuCount)
14 }
15
16// 物理机中获取 CPU 使用率
17 totalCpuPercent, err := cpu.Percent(time.Second, percpu)
18 if percpu {
19 // 获取具体的 CPU 核心对应的使用率
20 return totalCpuPercent[cpuIndex]
21 }
22 return totalCpuPercent[0]
23}
获取正确的 CPU 核心数
当用户指定 full load 参数时会对全部的核心注入 CPU 故障,那么如何获取当前环境中 CPU 核心数就非常重要了。
获取 CPU 核心数,可以使用 golang 中的 **runtime.NumCPU()**函数,但是在容器环境下这样获取是不准确的,runtime.NumCPU 函数返回的是容器所在宿主机的 CPU 核心数,而不是容器自身的 CPU 核心数 。其实这个问题的解决思路和上面获取 CPU 使用率有点相似,首先获取到当前进程的 cgroup 路径,然后读取 cpu.cfs_quota_us 和 cpu.cfs_period_us 文件去计算核心数。
计算规则:cpu.cfs_quota_us/cpu.cfs_period_us=容器核心数
1cpu_period_us:该文件用于设置 CPU 资源的周期时间。例如,如果将 cpu_period_us 设置为 100000 (100 ms),则 cgroup 中的进程可以在每个 100 毫秒的时间段内使用 CPU 资源。
2
3
4cpu_quota_us:该文件用于设置 CPU 资源的配额,如果 cpu_quota_us 的值小于 cpu_period_us,则表示对 CPU 资源进行限制。进程只能在 cpu_quota_us 设置的时间内使用 CPU,超过此时间将被限制。
在 ChaosBlade 中是利用 Uber 开源的 automaxprocs 库来设置核心数的,其底层实现分为 cgroup v1 和 v2 版本,在 cgroup v1 版本中就是按照上面说的方式实现的。
注入本质
其实注入的本质依然是 for 循环,根据用户设置的要注入的核心数量,开启对应的 goroutine,在 goroutine 里实现 for 循环,但是如何控制 CPU 负载的比例以及在指定时间范围内负载到目标值,则是需要特殊实现的。
填充(提升 CPU 负载)
代码路径在 cpu/cpu.go#burn func:burn 函数负责真正的提升 CPU 负载,接收的参数:
-
quota:负责更新要提升的配额(根据 CPU 使用率以及目标值进行计算)
-
slopePercent:填充的 CPU 比例(根据填充时间动态计算,如果填充时间为空则等于用户传入的填充比例)
-
percpu:是否让特定的 CPU 核心负载提升
-
cpuIndex:特定的 CPU 核心索引位置
重点代码通过注释标注:
1func burn(ctx context.Context, quota <-chan int64, slopePercent float64, percpu bool, cpuIndex int) {
2 // 获取初次填充负载的 CPU 配额(目标值),假设负载的 CPU 使用率=100,当前使用率=20,那么 q=800000000
3 q := getQuota(ctx, slopePercent, percpu, cpuIndex)
4 // 计算休息间隔=1000000000-800000000=200000000
5 ds := period - q
6 if ds < 0 {
7 ds = 0
8 }
9 // 计算休息间隔时间=200ms
10 s, _ := time.ParseDuration(strconv.FormatInt(ds, 10) + "ns")
11 for {
12 // 调度开始时间
13 startTime := time.Now().UnixNano()
14 select {
15 case offset := <-quota:
16 // 更新负载填充的配额
17 q = q + offset
18 if q < 0 {
19 q = 0
20 }
21 ds := period - q
22 if ds < 0 {
23 ds = 0
24 }
25 // 重新计算休息时间,(配额越大,休息时间越短)
26 s, _ = time.ParseDuration(strconv.FormatInt(ds, 10) + "ns")
27 default:
28 // for 循环占用 CPU,直到大于要填充的配额时停止
29 for time.Now().UnixNano()-startTime < q {
30 }
31 // 主动让出当前 goroutine 的执行时间片
32 runtime.Gosched()
33 // 休息,准备继续下次填充
34 time.Sleep(s)
35 }
36 }
37}
获取配额
代码路径在 cpu/cpu.go#getQuota func 中,首先获取 CPU 正确的使用率,然后计算当前要填充的配额 ,计算方式(要填充的比例-当前CPU使用率)
1func getQuota(ctx context.Context, slopePercent float64, percpu bool, cpuIndex int) int64 {
2 // 获取 CPU 正确的使用率
3 used := getUsed(ctx, percpu, cpuIndex)
4 // 计算当前要填充的配额 = 要填充的比例-使用率
5 // 填充的 CPU 比例(根据填充时间动态计算,如果填充时间为空则等于填充比例)
6 dx := (slopePercent - used) / 100
7 busy := int64(dx * float64(period))
8 return busy
9}
特定时间内 CPU 负载爬升到目标值
这里最重要的调控填充比例,填充比例的动态更新是根据填充时间参数(climbTime),动态计算出来的,利用定时器 Ticker 每秒更新一次
1func slope(ctx context.Context, cpuPercent int, climbTime int, slopePercent *float64, percpu bool, cpuIndex int) {
2 // 如果填充时间不等于 0
3 if climbTime != 0 {
4 // 创建定时器,每秒运行一次
5 var ticker = time.NewTicker(time.Second)
6 // 获取当前 CPU 使用率
7 *slopePercent = getUsed(ctx, percpu, cpuIndex)
8 // 获取起始 CPU 填充比例
9 var startPercent = float64(cpuPercent) - *slopePercent
10 go func() {
11 // 异步定时更新填充比例
12 for range ticker.C {
13 if *slopePercent < float64(cpuPercent) {
14 *slopePercent += startPercent / float64(climbTime)
15 } else if *slopePercent > float64(cpuPercent) {
16 *slopePercent -= startPercent / float64(climbTime)
17 }
18 }
19 }()
20 }
21}
指定具体核心负载
这里指的是根据用户参数 cpu-list,让特定某一个/几个核心使用率提升,而其他的核心不受影响,实现这一能力的核心是利用 Linux 的 taskset 命令。
在 Linux 系统中,taskset 是一个用于绑定或修改进程的 CPU 亲和性(CPU Affinity)的命令行工具。CPU 亲和性是指将一个或多个进程绑定到特定的 CPU 核心上,从而限制它们只在指定的 CPU 上运行,而不会在其他 CPU 上执行。这样做的目的是为了优化性能,减少由于在不同 CPU 之间切换导致的缓存失效和上下文切换的开销。
关键代码如下:
当用户输入 cpu-list 参数时,故障并没用真正的执行,而是利用 taskset 对具体核心以及故障命令做了亲和性绑定,然后重新调度的 cpu 故障指令,从而使故障指令和核心绑定。
1if cpuList != "" {
2// 遍历 cpu-list 参数
3 for _, core := range cores {
4 // 生成指定具体核心的 CPU 故障注入命令
5 args := fmt.Sprintf(`%s create cpu fullload --cpu-count 1 --cpu-percent %d --climb-time %d --cpu-index %s --uid %s`,
6 os.Args[0], cpuPercent, climbTime, core, ctx.Value(spec.Uid))
7 // 将 taskset -c 参数绑定指定的核心和要执行的故障注入命令
8 args = fmt.Sprintf("-c %s %s", core, args)
9 argsArray := strings.Split(args, " ")
10 // 运行 taskset
11 command := os_exec.CommandContext(ctx, "taskset", argsArray...)
12 command.SysProcAttr = &syscall.SysProcAttr{}
13 if err := command.Start(); err != nil {
14 return spec.ReturnFail(spec.OsCmdExecFailed, fmt.Sprintf("taskset exec failed, %v", err))
15 }
16 }
回滚
停止 CPU 故障注入的实现相对简单很多,只需要找到故障注入指令运行的进程,然后 kill 掉即可。
1ps, _ := cl.GetPidsByProcessName("chaos_os", ctx)
2pids = append(ps, pids...)
3return cl.Run(ctx, "kill", fmt.Sprintf(`-9 %s`, strings.Join(pids, " ")))
实践遇到的问题
当在 K8S 物理机中注入 CPU 满载(使用率 100%)故障时,有可能会出现 CPU 使用率不能达到 100%。
如果出现这种情况,需要观察下是不是物理中的容器的 CPU 优先级设置的比较高,当一个容器的 CPU 优先级较高(即设置了较大的 cpu.shares 或其他相应的参数),容器内的进程将会优先获得 CPU 时间片。这会导致容器内的进程在竞争 CPU 资源时优先运行,而物理机上其他进程则可能因为 CPU 时间片被抢占而获得较少的 CPU 时间,从而影响了其他进程的 CPU 使用。
总结
ChaosBlade 是一个用于模拟故障的工具,旨在帮助开发人员和管理员了解系统性能,增强系统稳定性,并提高应对故障的能力。
本文介绍了 ChaosBlade 模拟 CPU 负载升高的使用方式及其底层实现,通过这篇文章,了解到如何使用 ChaosBlade 工具进行 CPU 负载模拟,从而更好地了解系统性能,优化系统稳定性,并提高处理故障的能力。同时,还了解到在容器环境下获取正确的 CPU 使用率和核心数的方法,以及对特定核心进行负载注入的实现原理。
作者介绍
Github 账号:binbin0325,公众号:柠檬汁Code,Sentinel-Golang Committer 、ChaosBlade Committer 、 Nacos PMC 、Apache Dubbo-Go Committer。目前主要关注于混沌工程、中间件以及云原生方向。
