语言背景
Golang
Google 为什么要创建 Go
- 计算机硬件技术更新频繁,性能提高很快。目前主流的编程语言发展明显落后于硬件,不能合理利用多核多 CPU 的优势提升软件系统性能。
- 软件系统复杂度越来越高,维护成本越来越高,目前缺乏一个足够简洁高效的编程语言。
-
- 现有编程语言存在:风格不统一、计算能力不够、处理大并发不够好
- 企业运行维护很多 c/c++的项目,c/c++程序运行速度虽然很快,但是编译速度确很慢,同时还存在内存泄漏的一系列的困扰需要解决。
Go 语言发展历史
- 2007 年,谷歌工程师 Rob Pike,Ken Thompson 和 Robert Griesemer 开始设计一门全新的语言,这是 Go 语言的最初原型。
- 2009 年 11 月 10 日,Google 将 Go 语言以开放源代码的方式向全球发布。
- 2015 年 8 月 19 日,Go1.5 版发布,本次更新中移除了”最后残余的 c 代码”
- 2017 年 2 月 17 日,Go 语言 Go1.8 版发布。
- 2017 年 8 月 24 日,Go 语言 Go1.9 版发布。
- 2018 年 2 月 16 日,Go 语言 Go1.10 版发布。
- 截止至今,Go语言最新版本v1.22.1版本发布。
Java
Java的发展历史可以追溯到20世纪90年代初,以下是Java的一些关键时刻和发展阶段:
- 1991年:Oak 项目启动: James Gosling、Mike Sheridan和Patrick Naughton等Sun Microsystems的工程师开始了一个名为Oak的项目,旨在开发一种用于嵌入式系统的语言。
- 1994年:Java 语言诞生: Oak 项目演变成了Java项目,该语言在Sun Microsystems的Java小组领导下于1995年5月正式发布。Java被设计成一种简单、面向对象、可移植、高性能的编程语言。
- 1995年:公开发布: Java 1.0版本正式发布,引入了许多今天仍然存在的基本特性,例如Java虚拟机(JVM)和Applet技术。
- 1997年:Java 1.1发布: 引入内部类、JavaBean、RMI(远程方法调用)等特性,增强了语言的功能。
- 1998年:Java 2发布: Java 2(J2SE 1.2)发布,引入了Swing GUI工具包、集合框架、Java Naming and Directory Interface(JNDI)等重要特性。
- 2000年:Java 2 Enterprise Edition(J2EE)发布: 针对企业级应用程序开发推出,引入了Servlet、JSP(JavaServer Pages)等技术。
- 2004年:Java 5.0发布: 引入了重要的语言特性,如泛型、枚举、注解、自动装箱和拆箱、增强的for循环等。
- 2006年:Java 6发布: 引入了Java虚拟机的更新、Scripting API、Java Compiler API等新特性。
- 2011年:Java 7发布: 引入了重要的语言特性,如try-with-resources语句、钻石操作符、字符串在switch语句中的支持等。
- 2014年:Java 8发布: 引入了Lambda表达式、Stream API、新的Date和Time API等重要特性,对语言和库进行了重大的升级。
- 2017年:Java 9发布: 引入了模块化系统、改进的Javadoc、集合工厂方法等新特性。
- 2018年:Java 10发布: 引入了局部变量类型推断、改进的垃圾回收器等新特性。
- 2019年:Java 11发布: 引入了HTTP Client API、局部变量类型推断的升级、动态类文件常量等新特性。此版本标志着Oracle对长期支持(LTS)版本的承诺。
- 2021年:Java 17发布: 作为一个长期支持(LTS)版本,引入了Sealed Classes、Pattern Matching for Switch、新的垃圾回收器等特性。
Java的发展一直在持续进行,保持了与时俱进的态势。它在企业级应用、移动开发、大数据、云计算等领域都有着广泛的应用,成为世界上最受欢迎的编程语言之一。
语言特点
Go 语言的特点
- Go 也是一种静态的编译型语言,语法和 C 相近,从 c 语言中继承了很多理念,包括表达式语法,控制结构,基础数据类型,调用参数传值,指针等等
- 垃圾回收机制,内存自动回收
- 天然并发【重要特点】
- 从语言层面支持并发,实现简单
- goroutine,轻量级线程,可实现大并发处理,高效利用多核。
- 基于 CSP 并发模型(Communicating Sequential Processes,通讯顺序进程)实现
- 吸收了管道通信机制,形成 go 语言特有的管道 channel,通过管道 channel,可以实现不同的 goroute 之间的相互通信
- 函数返回多个值
- 新的创新:比如切片 slice,延时执行 defer 等
Java 语言的特点
1.简单
Java 最初是为对家用电器进行集成控制而设计的一种语言,因此它必须简单明了。Java 语言的简单性主要体现在以下三个方面:
- Java 的风格类似于 C++,因而 C++程序员是非常熟悉的。从某种意义上讲,Java 语言是 C 及 C++语言的一个变种,因此,C++程序员可以很快就掌握 Java 编程技术。
- Java 摒弃了 C++中容易引发程序错误的地方,如指针和内存管理。
- Java 提供了丰富的类库。
2.面向对象
面向对象可以说是 Java 最重要的特性。Java 语言的设计完全是面向对象的,它不支持类似 C 语言那样的面向过程的程序设计技术。Java 支持静态和动态风格的代码继承及重用。单从面向对象的特性来看,Java 类似于 Small Talk,但其它特性、尤其是适用于分布式计算环境的特性远远超越了 Small Talk。
3.可移植
“一次编译,到处运行“的设计初衷,将代码编译为字节码后,即可运行在 JVM 虚拟机上。无视系统环境的差异。
4.解释执行+即时编译
在程序运行初始,是通过 JVM 中的解释器运行通过 javac(前端编译器)编译生成的 JVM 字节码,解释器会将我们的代码一句一句解释成机器可以识别的二进制代码来执行,可以认为是,解释一句,执行一句,效率较低
在程序运行期间,是通过及时编译器(JIT)把字节码转成机器码。JIT 及时编译在 JDK 1.7 以前主要是 HotSpot VM 的 C1、C2 编译器,在 JDK 1.7 开始后引入了分层编译,将 C1,C2 进行结合更好的提升程序的编译以及运行效率
5.动态编译
动态编译,简单来说就是在 Java 程序运行时编译源代码。
从 JDK1.6 开始,引入了 Java 代码重写过的编译器接口,使得我们可以在运行时编译 Java 源代码,然后再通过类加载器将编译好的类加载进 JVM,这种在运行时编译代码的操作就叫做动态编译。
6.多线程
Java 语言是多线程的,这也是 Java 语言的一大特性,它必须由 Thread 类和它的子类来创建。Java 支持多个线程同时执行,并提供多线程之间的同步机制。
7.垃圾回收
java 语言支持多种垃圾回收机制,不需要开发者手动回收内存。 其中包括 CMS,G1,ZGC
8.注解
Java 注解(Annotation)又称 Java 标注,是 JDK5.0 引入的一种注释机制。Java 语言中的类、方法、变量、参数和包等都可以被标注。和 Javadoc 不同,Java 标注可以通过反射获取标注内容。在编译器生成类文件时,标注可以被嵌入到字节码中
典型项目
Golang
- Kubernetes
Kubernetes ,也称为 K8s,是一个用于跨多个主机管理容器化应用程序的开源系统。它为应用程序的部署、维护和扩展提供了基本机制
- Docker
Docker 用于开发应用、交付(shipping)应用、运行应用。Docker 允许用户将基础设施中的应用单独分割出来,形成更小的颗粒(容器),从而提高交付软件的速度
- Etcd
Etcd 是分布式系统中最关键数据的分布式可靠键值存储系统
- Tidb
Tidb 是一个开源的分布式 SQL 数据库,支持混合事务和分析处理(HTAP)工作负载。它与 MySQL 兼容,具有水平可扩展性、强一致性和高可用性。
Java
- Spring
Spring 提供了 Java 编程语言以外的一切所需功能,用于为各种场景和体系结构创建企业应用程序
- Spring boot
Spring Boot 帮助您以最小的麻烦创建 Spring 驱动的产品级应用程序和服务。它对 Spring 平台有自己的看法,以便新用户和现有用户可以快速获得所需的部分
- Elasticsearch
Elasticsearch 是位于 Elastic Stack 核心的分布式 RESTful 搜索和分析引擎
- Dubbo
Apache Dubbo 是一个高性能、基于 java 的开源 RPC 框架
编码
关键字
golang有25个关键字

java有51个关键字

规约
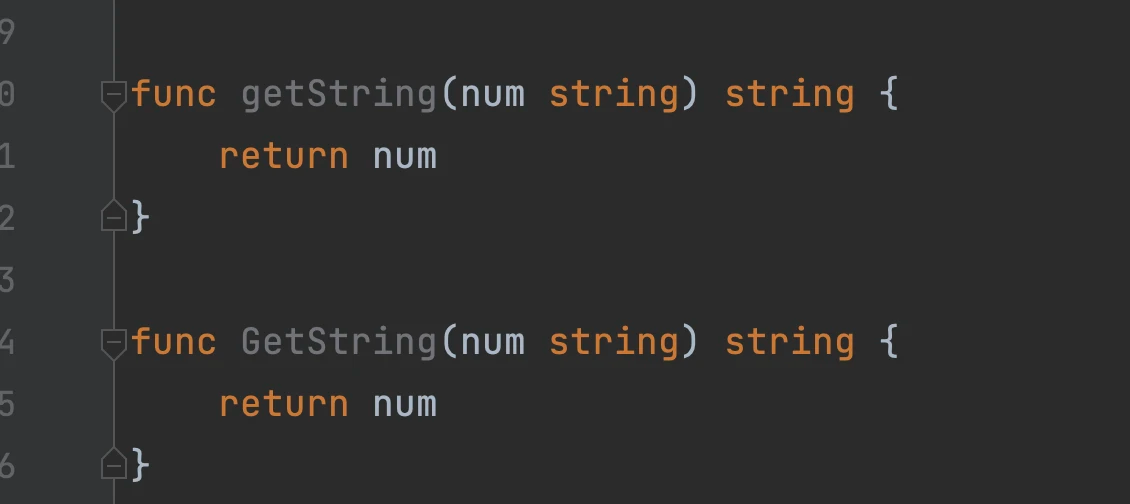
Golang 是一门严格的工程语言,主要体现在编码风格及可见域规则上,在 Java 中,允许多种编码风格共存,譬如以下两种方法声明,对于 Java 来说都是允许的:
1public String getString(Integer num) {
2 return num.toString();}
3public String getString(Integer num) {
4 return num.toString();
5}
在 Golang 中则是会严格检查换行风格,如果出现上面的情况会直接提示编译错误
变量声明
在 Java 中,变量可以声明了却不使用,而 Golang 中声明的变量必须被使用,否则需要使用_来替代掉变量名,表明该变量不会被使用到:
1func getString(num int) string {
2 temp := num
3 _ := num
4 return strconv.Itoa(num)}
在 Golang 中支持两种变量声明方式,方式 2 会有编译器自动推导类型,更简洁一些
1方式 1: var a string
2方式 2:b := 1
在 Golang 中对于基本类型,声明即初始化;对于引用类型,声明则初始化为 nil,在 Java 中,如果在方法内部声明一个变量但不初始化,在使用时会出现编译错误:
1public void solve() {
2 int num;
3 Object object;
4 System.out.println(num);
5 System.out.println(object);
6 }
可见域规则
Java 对方法、变量及类的可见域规则是通过 private、protected、public 关键字来控制的,而 Golang 中控制可见域的方式只有一个,当字段首字母开头是大写时说明其是对外可见的、小写时只对包内成员可见。
参数传递
在 java 中参数传递有两种,一种是引用传递,一种是值传递。而在 Golang 中一切均为值传递。
例如数组在 Java 中是引用传递,当数组被当作参数传递到方法中,在方法内部对可以对数组中的内容修改。 在 Golang 中则会完全深度 copy 一份数组在方法中。
但是在 Golang 中有指针的概念,可以通过传递参数的指针来进行修改参数原有内容,但这种也是值传递,本质上是将指针的地址进行了深度 copy。相当于两个指针同时指向了参数的真正内存地址
结构体声明及使用
在 Golang 中区别与 Java 最显著的一点是,Golang 不存在“类”这个概念,组织数据实体的结构在 Golang 中被称为结构体。函数可以脱离“类”而存在,函数可以依赖于结构体来调用或者依赖于包名调用。
Golang 中的结构体放弃了继承、实现等多态概念,结构体之间可使用组合来达到复用方法或者字段的效果。
要声明一个结构体只需使用 type + struct 关键字即可:
1type Person struct {
2 Name string
3 Age int
4 id string}
要使用一个结构体也很简单,一般有以下几种方式去创建结构体:
1 personPoint := new(entity.Person)
2 person1 := entity.Person{}
3 person2 := entity.Person{
4 Name: "ARong",
5 Age: 21,
6 }
异常处理
在 java 中通过 try catch 对异常进行处理,在 go 语言里是没有 try catch 的概念的,因为 try catch 会消耗更多资源,而且不管从 try 里面哪个地方跳出来,都是对代码正常结构的一种破坏。
所以 go 语言的设计思想中主张如果一个函数可能出现异常,那么应该把异常作为返回值,没有异常就返回 nil 每次调用可能出现异常的函数时,都应该主动进行检查,并做出反应。
1type Student struct {
2 name string
3}
4func main() {
5 name, err := GetName(&Student{})
6 if err != nil {
7 fmt.Println("error", err)
8 return
9 }
10 fmt.Println(name)
11}
12
13
14func GetName(s *Student) (string, error) {
15 if s.name == "" {
16 return "", errors.New("not found name")
17 }
18 return "Evan", nil
19}
重写与重载
在 Golang 中没有继承的概念,但是可以通过结构体组合的方式来达到“继承”的效果。
1type Parent struct {
2 name string
3}
4type Child struct {
5 Parent
6 name string
7}
8func (p *Parent) Name() string {
9 return p.name
10}
11func (c *Child) Name() string {
12 return c.Parent.Name()
13}
重载也不如 java 那样灵活,在 java 中重载的要求是:在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
在 Golang 中可以通过接口来实现类似的效果,但是方法参数和返回值必须相同
1type Info interface {
2 Name() string
3}
4type A struct {
5 name string
6}
7type B struct {
8 firstName string
9 lastName string
10}
11func (a *A) Name() string {
12 return a.name
13}
14func (b *B) Name() string {
15 return b.firstName + b.lastName
16}
多线程
在 java 中使用多线程,如果不考虑线程池的情况下,也需要继承 Thread 类或者实现 Runnable/Callable 接口,相对比较繁琐。
1public class Task extends Thread {
2 @Override
3 public void run() {
4 }
5 public static void main(String[] args) {
6 new Task().start();
7 }
8}
如果考虑资源问题(例如线程启动太多可能会造成 CPU 上下文频繁切换,性能反而降低。线程创建太多也会大量消耗内存),还需要考虑通过线程池来创建线程 ,更加繁琐。
而在 Golang 中,golang 通过自身的 GMP 调度机制,用户只需要使用 Go 关键字创建 goroutine 协程即可,协程非常轻量,每个协程的初始大小在 2kb 左右。
协程(用户级线程),这是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的。在 golang 中通过 go 关键字开启协程,协程是属于用户态的减少了多线程情况下的 CPU 切换,在高并发场景下效果更好。
1func main() {
2 for i := 0; i < 100; i++ {
3 go func() {
4 fmt.Println("你好")
5 }()
6 }
7}
垃圾回收
在 java 和 golang 中都有垃圾回收机制。常见的垃圾回收算法如下:
- 标记-清除:从根变量开始遍历所有引用的对象,标记引用的对象,没有被标记的进行回收。
- 优点:算法简单。
- 缺点:需要 STW,效率不稳定,内存空间碎片化。
- 标记-复制:为了解决标记-清除算法面对大量可回收对象时执行效率低的问题,1969 年 Fenichel 提出了一种称为“半区复制”(Semispace Copying)的垃圾收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着 的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉
- 优点:实现简单,运行高效,没有碎片
- 缺点:空间浪费严重,可用内存缩小为原来一半
- 标记-整理:其中的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存。
- 优点:没有内存碎片
- 缺点:部分场景不适合,如果进行回收时有大量存活对象,那么需要移动对象并更新所有引用,效率低下,因为这种操作需要 STW。
Java
在 java 中有 Serial,ParNew,CMS,G1,ZGC 多种垃圾收集器,其实 CMS,G1,ZGC 通过分代垃圾回收思想。将“朝生夕死”的对象和“经久不衰”的对象按照不同的内存区域区分开来。
其中 CMS 收集器是一款基于标记-清除算法实现的收集器(有碎片化问题),老年代则使用标记-整理算法实现。
在 G1 收集器中 (1.7 引入,1.9 默认启用),遵循分代收集理论设计,但是淡化了堆内存按照分代划分的概念,G1 不再坚持固定大小以及固定数量的分代区域划分,而是把连续的 Java 堆划分为多个大小相等的独立区域(Region),每一个 Region 都可以根据需要,扮演新生代的 Eden 空间、Survivor 空间,或者老年代空间 ,而有了 Region 概念后,在回收过程中只需要把需要回收的 Region 中的存活对象复制到空 Region 中,然后清理掉整个旧 Region 空间。 相当于 G1 收集器是采用了标记-复制+清除的算法
ZGC 收集器是一款基于 Region 内存布局的(与 G1 相同),不设分代,使用了读屏障、染色指针和内存多重映射等技术来实现可并发的标记算法的,以低延迟为首要目标的一款垃圾收集器
Golang
在 Golang 中垃圾回收算法选择了标记-清除,通过“三色标记”算法进行标记,通过多层级的内存分配算法,尽可能解决内存碎片化的问题。 利用写屏障+辅助 GC 缩短 STW
三色标记相关介绍文章: https://mp.weixin.qq.com/s/G7id1bNt9QpAvLe7tmRAGw
内存分配
编程语言的内存分配器一般包含两种分配方法,一种是线性分配器(Sequential Allocator,Bump Allocator),另一种是空闲链表分配器(Free-List Allocator)
线性分配器
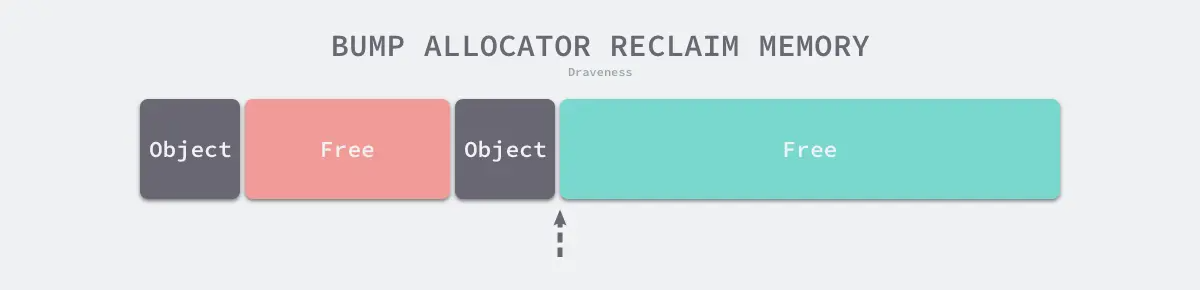
线性分配(Bump Allocator)是一种高效的内存分配方法,但是有较大的局限性。当我们使用线性分配器时,只需要在内存中维护一个指向内存特定位置的指针,如果用户程序向分配器申请内存,分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置,即移动下图中的指针:

虽然线性分配器实现为它带来了较快的执行速度以及较低的实现复杂度,但是线性分配器无法在内存被释放时重用内存。如下图所示,如果已经分配的内存被回收,线性分配器无法重新利用红色的内存:
因为线性分配器具有上述特性,所以需要与合适的垃圾回收算法配合使用,例如:标记压缩(Mark-Compact)、复制回收(Copying GC)和分代回收(Generational GC)等算法,它们可以通过拷贝的方式整理存活对象的碎片,将空闲内存定期合并,这样就能利用线性分配器的效率提升内存分配器的性能了。
空闲链表分配器
空闲链表分配器(Free-List Allocator)可以重用已经被释放的内存,它在内部会维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表:
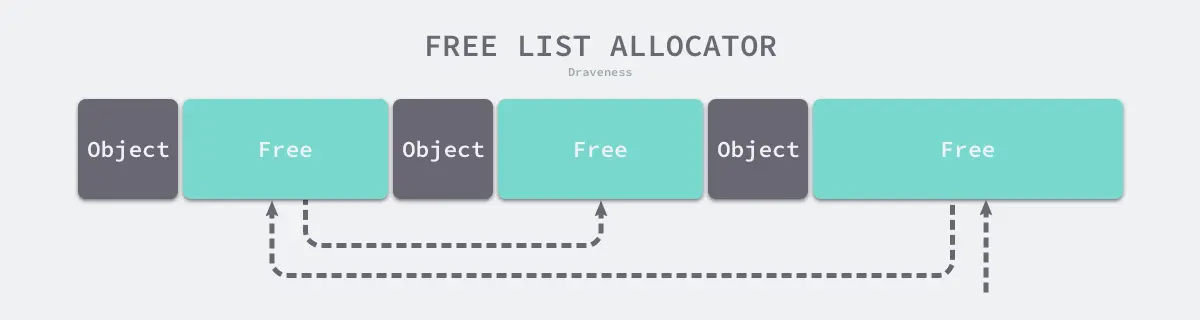
因为不同的内存块通过指针构成了链表,所以使用这种方式的分配器可以重新利用回收的资源,但是因为分配内存时需要遍历链表,所以它的时间复杂度是 𝑂(𝑛)
空闲链表分配器可以选择不同的策略在链表中的内存块中进行选择,最常见的是以下四种:
- 首次适应(First-Fit)— 从链表头开始遍历,选择第一个大小大于申请内存的内存块;
- 循环首次适应(Next-Fit)— 从上次遍历的结束位置开始遍历,选择第一个大小大于申请内存的内存块;
- 最优适应(Best-Fit)— 从链表头遍历整个链表,选择最合适的内存块;
- 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块;
上述四种策略的前三种就不过多介绍了,Go 语言使用的内存分配策略与第四种策略有些相似,我们通过下图了解该策略的原理:

如上图所示,该策略会将内存分割成由 4、8、16、32 字节的内存块组成的链表,当我们向内存分配器申请 8 字节的内存时,它会在上图中找到满足条件的空闲内存块并返回。隔离适应的分配策略减少了需要遍历的内存块数量,提高了内存分配的效率。
**java 使用的是线性分配器,golang 使用的是空闲链表分配器,从而一定程度上解决了内存碎片化问题 **
golang内存分配相关文章:https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/
线程模型
使用用户线程实现(多对一模型 M:1)
广义上来讲,一个线程只要不是内核线程,都可以是用户线程(User Threa,UT)的一种。多个用户线程映射到一个内核线程,用户线程建立在用户空间的线程库上,用户线程的建立、同步、销毁和调度完全在用户态中完成,对内核透明。果程序实现得当,不需要切换内核态,因此操作可以是非常快且低消耗的,也能够支持规模更大的线程数量,部分高性能数据库中的多线程就是由用户线程实现的。
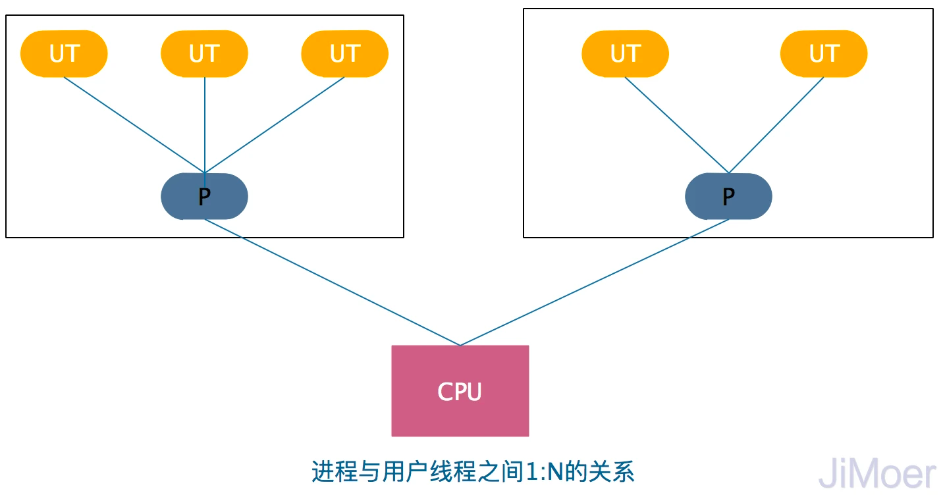
优点:
- 线程的上下文切换都发生在用户空间,避免了模态切换(mode switch),减少了性能的开销。
- 用户线程的创建不受内核资源的限制,可以支持更大规模的线程数量。
缺点:
- 所有的线程基于一个内核调度实体即内核线程,这意味着只有一个处理器可以被利用,浪费了其它处理器资源,不支持并行,在多处理器环境下这是不能够被接受的,如果线程因为 I/O 操作陷入了内核态,内核态线程阻塞等待 I/O 数据,则所有的线程都将会被阻塞。
- 增加了复杂度,所有的线程操作都需要用户程序自己处理,而且在用户空间要想自己实现 “阻塞的时候把线程映射到其他处理器上” 异常困难。
使用内核线程实现(一对一模型 1:1)
使用内核线程实现的方式被称为 1:1 实现。内核线程(Kernel Levvel Thread,KLT)就是直接由操作系统内核(Kernel,下称内核)支持的线程,内核通过操纵调度器(Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。其实程序一般不会直接使用内核线程,程序使用的是内核线程的一种高级接口——轻量级进程(Light Weight Process,LWP),轻量级进程就是我们通常意义上所讲的线程,轻量级进程也是属于用户线程。
每个用户线程都映射到一个内核线程,每个线程都成为一个独立的调度单元,由内核调度器独立调度,一个线程的阻塞不会影响到其他线程,从而保障整个进程继续工作。
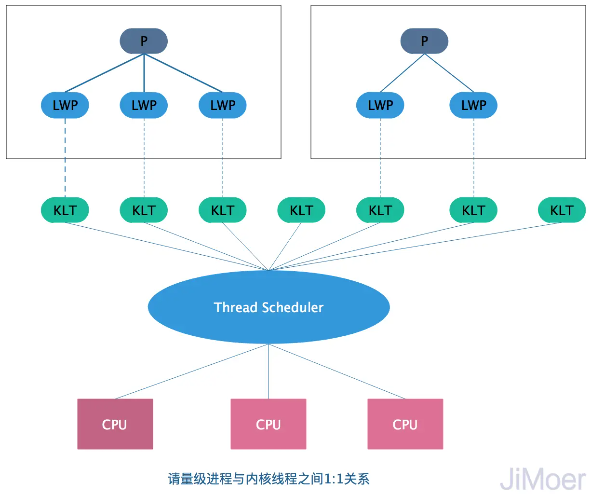
优点:
- 每个线程都成为一个独立的调度单元,使用内核提供的线程调度功能及处理器映射,可以完成线程的切换,并将线程的任务映射到其他处理器上,充分利用多核处理器的优势,实现真正的并行。
缺点:
- 每创建一个用户级线程都需要创建一个内核级线程与其对应,因此需要消耗一定的内核资源,而内核资源是有限的,所以能创建的线程数量也是有限的。
- 模态切换频繁,各种线程操作,如创建、析构及同步,都需要进行系统调用,需要频繁的在用户态和内核态之间切换,开销大。
使用用户线程加轻量级进程混合实现(多对多模型 M:N)
内核线程和用户线程的数量比为 M : N,这种模型需要内核线程调度器和用户空间线程调度器相互操作,本质上是多个线程被映射到了多个内核线程。
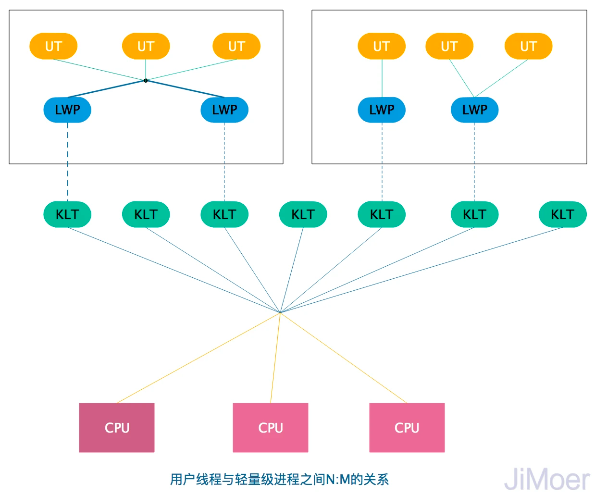
综合了前面两种模型的优点:
- 用户线程的创建、切换、析构及同步依然发生在用户空间,能创建数量更多的线程,支持更大规模的并发。
- 大部分的线程上下文切换都发生在用户空间,减少了模态切换带来的开销。
- 可以使用内核提供的线程调度功能及处理器映射,充分利用多核处理器的优势,实现真正的并行,并降低了整个进程被完全阻塞的风险
java 使用 1:1 模型,而 golang 使用 M:N 模型
java线程相关文章:https://blog.csdn.net/qq_35165000/article/details/107239532
golang GMP调度相关文章:https://mp.weixin.qq.com/s/9MfIdUdBZmfqbUYT_xrB8A
效率
java-go-rust 性能对比: https://tonybai.com/2020/05/01/comparison-between-java-go-and-rust/
web 框架性能测试榜单: https://www.techempower.com/benchmarks/#section=data-r21&hw=ph&test=composite (参考可以,适合的才是最好的)
作者介绍
Github 账号:binbin0325,公众号:柠檬汁Code,Sentinel-Golang Committer 、ChaosBlade Committer 、 Nacos PMC 、Apache Dubbo-Go Committer。目前主要关注于混沌工程、中间件以及云原生方向。
