1. 前文回顾
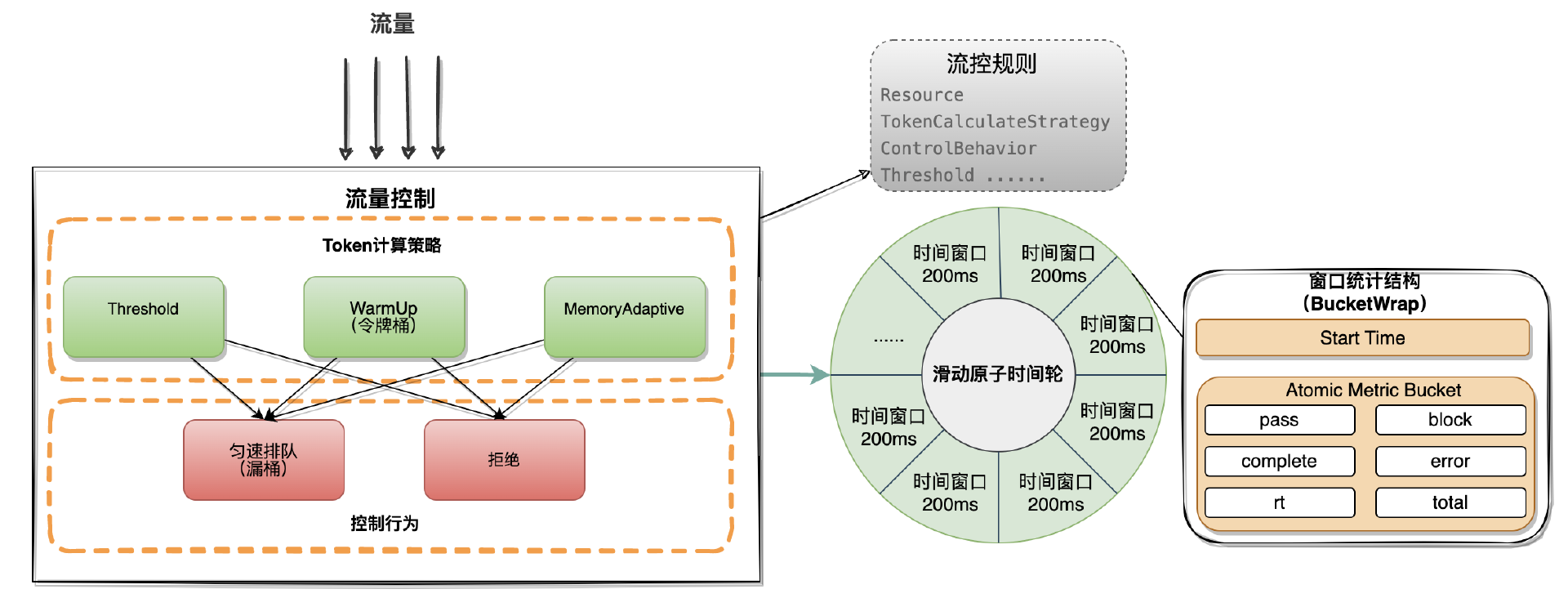
在上文中介绍了流量控制的实现原理,流量控制本质是根据资源所属的流控规则以及滑动时间窗口统计结构,对流量统计与计算从而控制流量的行为。
资源是一个抽象的概念,它可以是系统中的任何一个可识别的资源,比如一个 HTTP 接口、一个 Dubbo 服务、一个数据库访问或是一个 MQ 消息队列
2. 介绍
本文将会介绍Sentinel-Go中的热点参数流控的使用场景以及实现原理,下面我会举例说明什么是热点参数流控以及它的的使用场景。
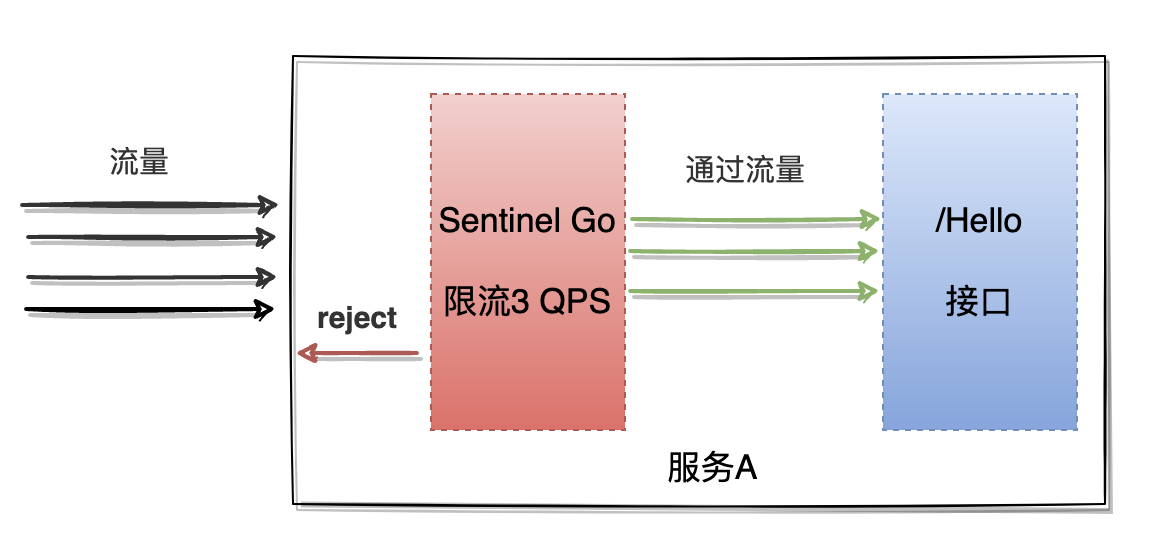
假设想要针对一个HTTP接口进行限流,接口每秒被请求超过3次则对流量进行限流,在这个场景下使用上文介绍的流量控制是可以满足的,限流效果如下图:
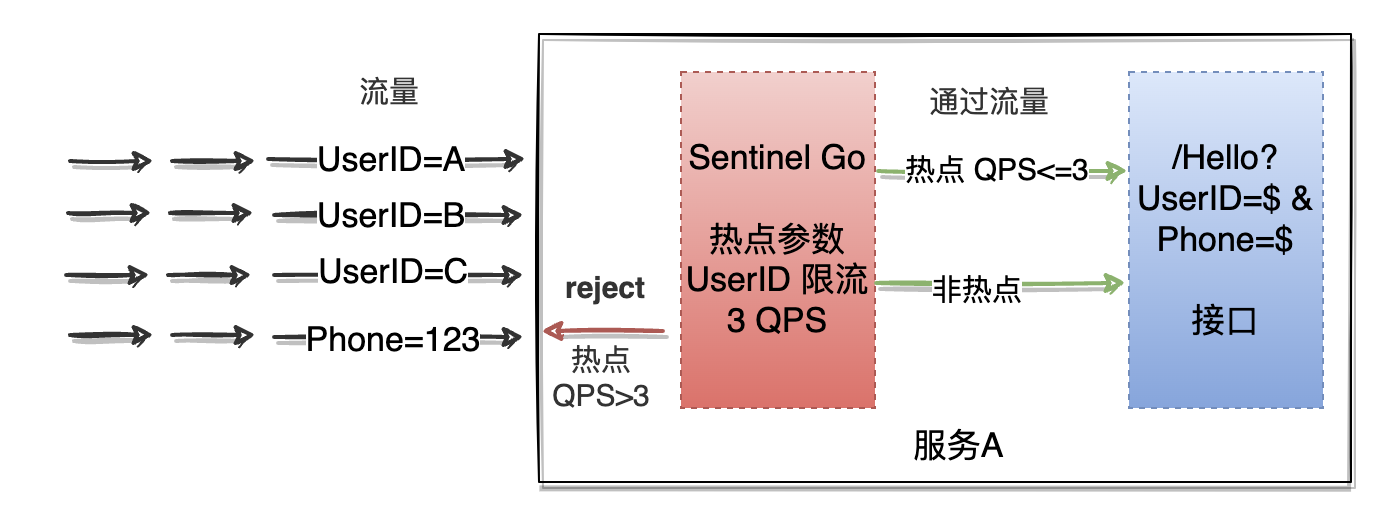
假设现在访问Hello接口需要传递用户ID参数,然后想要针对一段时间内频繁访问的用户 ID 进行限流,也就是我们的限流需求想要更加细粒度的控制,使用上文介绍的流量控制还可以吗?
答案:理论上是可以的,但实际上很难完成。首先我们需要知道所有可能访问这个接口的用户ID并对所有用户ID创建流量控制的限流规则,但在现实场景下是无法做到的,因为用户可能随时会有新增,我们无法预先知道所有的用户ID,其次每个用户都创建限流规则这个成本也会非常高。
在这种需求下热点参数流控应运而生,热点参数流控中最关键的词就是热点,热点即是代表经常访问的数据。在上面描述的场景中我们希望统计热点参数(UserID)访问频次最高的 Top K 用户,并对其超过限流阈值的访问进行限制,热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效
热点参数流控:
3. 流控规则
了解了什么是热点数据流控,下面看一下在Sentinel-Go中对应的热点参数流控规则
1type Rule struct {
2 // 资源名,即规则的作用目标。
3 Resource string `json:"resource"`
4 // 流量的统计类型,支持Concurrency(并发)和QPS两种
5 // Concurrency:当并发个数超过阈值,则直接拒绝
6 // QPS:当QPS超过阈值,则由ControlBehavior来控制流量的行为
7 MetricType MetricType `json:"metricType"`
8 // 控制超过阈值的流量行为,支持直接拒绝以及匀速排队
9 ControlBehavior ControlBehavior `json:"controlBehavior"`
10 // 热点参数的索引下标,Sentinel计算时会按照热点参数下标到参数列表中进行获取
11 ParamIndex int `json:"paramIndex"`
12 // 热点参数的key,ParamKey可以到做ParamIndex的补充,方便用户使用,从而不需要将参数列表与热点参数下表进行对应
13 ParamKey string `json:"paramKey"`
14 // 流控阈值
15 Threshold int64 `json:"threshold"`
16 // 匀速排队的最大等待时间,该字段仅仅对控制行为是匀速排队时生效
17 MaxQueueingTimeMs int64 `json:"maxQueueingTimeMs"`
18 // 流控阈值预留buff
19 // 仅在MetricType=QPS并且ControlBehavior=Reject时生效
20 BurstCount int64 `json:"burstCount"`
21 // 统计时间间隔
22 DurationInSec int64 `json:"durationInSec"`
23 // 热点参数统计的最大容量
24 ParamsMaxCapacity int64 `json:"paramsMaxCapacity"`
25 // 特殊热点参数的特殊限流阈值(例如针对所有UserId限流阈值为100,但想单独对UserId=张三的用户限流阈值为200时使用)
26 SpecificItems map[interface{}]int64 `json:"specificItems"`
27}
4. 热点参数流控
4.1 流控方式
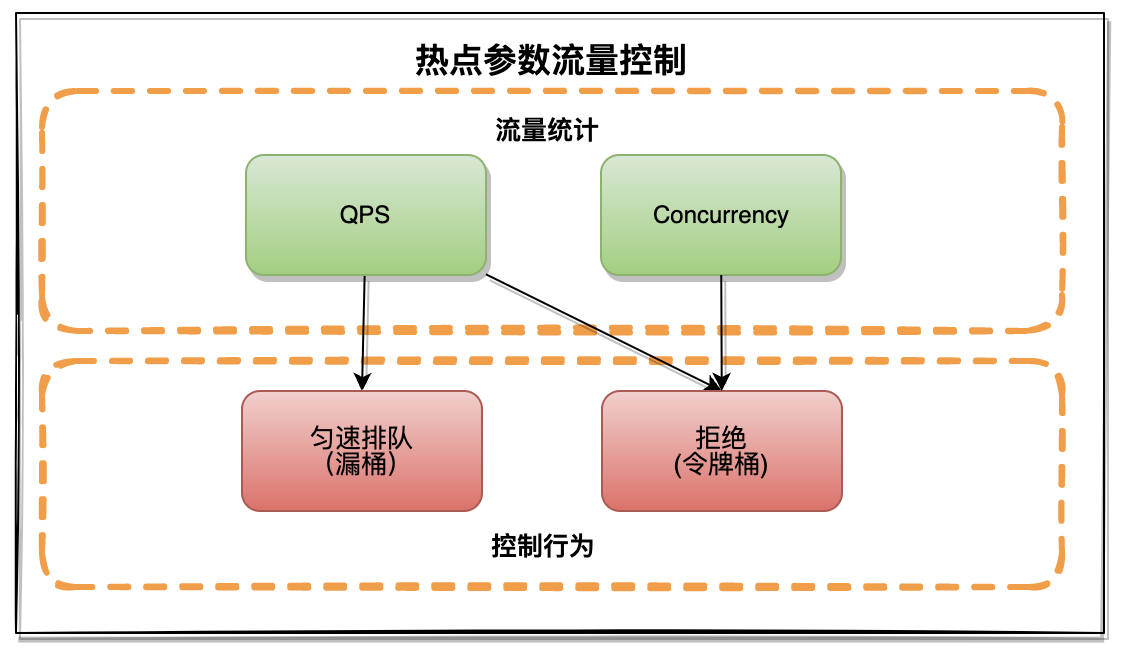
通过上面的流控规则可以看出,在热点参数流控中是根据MetricType+ControlBehavior组合来提供不同的流控策略,相比于流量控制的多种流控方式热点参数流控方式只有三种:
-
Concurrency+Reject:并发超过阈值直接拒绝的流控方式
-
QPS+Reject:QPS超过阈值直接拒绝
-
QPS+Throttling:QPS超过阈值匀速排队
4.2 统计结构
在流量控制中流量是利用底层的滑动时间窗口进行统计的,那么在热点参数流控中还可以继续使用滑动时间窗口进行流量统计吗?
答案:不可以,因为热点参数流控的特点(1.参数的值数量不固定,可能会非常多 2. 只需要统计一段时间内的热点数据),如果继续使用滑动时间窗口则会演变成每个UserID一个统计结构,哪怕是这个UserID只有一次请求。这样的资源浪费是没有必要的,我们只需要统计一段时间内的热点数据的请求次数,对于非热点数据进行淘汰即可,这样则可以节省内存空间。
在常见的缓存淘汰算法中有LRU和LFU
-
LRU算法:(Least Recently Used)最近最少使用的数据会被淘汰,而最近频繁使用的数据会留在缓存中
-
LFU算法:(Least Frequently Used)最不经常使用的数据会被淘汰,它是一种根据数据使用频率来进行缓存淘汰的算法,当缓存空间不足时,LFU 算法会优先淘汰访问频率最低的数据。
热点数据的统计比较符合LRU算法的特点,所以在Sentinel Go中选择使用LRU 策略统计最近最常访问的热点参数,下面来看一下具体的工程实现:
首先在hotspot模块下有一个Cache目录,在Cache目录里有ConcurrentCounterCache 接口,此接口是对热点参数统计结构的抽象,实现此接口就可以作为热点参数限流的统计结构
1type ConcurrentCounterCache interface {
2 Add(key interface{}, value *int64)
3 AddIfAbsent(key interface{}, value *int64) (priorValue *int64)
4 Get(key interface{}) (value *int64, isFound bool)
5 Remove(key interface{}) (isFound bool)
6 Contains(key interface{}) (ok bool)
7 Keys() []interface{}
8 Len() int
9 Purge()
10}
在Cache目录下的concurrent_lru.go文件中是ConcurrentCounterCache接口的具体实现,concurrent_lru中实现了并发安全的lru算法
1type LruCacheMap struct {
2 // Not thread safe
3 lru *LRU
4 lock *sync.RWMutex
5}
6func (c *LruCacheMap) Add(key interface{}, value *int64) {
7 c.lock.Lock()
8 defer c.lock.Unlock()
9 c.lru.Add(key, value)
10 return
11}
12func (c *LruCacheMap) Get(key interface{}) (value *int64, isFound bool) {
13 c.lock.Lock()
14 defer c.lock.Unlock()
15 val, found := c.lru.Get(key)
16 if found {
17 return val.(*int64), true
18 }
19 return nil, false
20}
21//省略部分代码 ......
在Cache目录下的lru.go中则是lru算法的真正实现,也是热点数据真正存储的数据结构(在LRU算法中Add,Get等操作会将元素移动到队列头部,当元素中个数超过容量时会将队尾元素淘汰)
1type LRU struct {
2 size int
3 evictList *list.List
4 items map[interface{}]*list.Element
5 onEvict EvictCallback
6}
7func (c *LRU) Add(key, value interface{}) {
8 // Check for existing item
9 if ent, ok := c.items[key]; ok {
10 c.evictList.MoveToFront(ent)
11 ent.Value.(*entry).value = value
12 return
13 }
14 // Add new item
15 ent := &entry{key, value}
16 entry := c.evictList.PushFront(ent)
17 c.items[key] = entry
18 evict := c.evictList.Len() > c.size
19 // Verify size not exceeded
20 if evict {
21 c.removeOldest()
22 }
23 return
24}
25//省略部分代码 ......
在hotspot模块下的params_metric.go文件中,声明了ParamsMetric 结构,ParamsMetric就是热点参数的统计结构,在不同的控制行为中对统计结构中的LRU有不同的使用方式:
1// 热点参数的计数器,key=热点参数的值,value=计数器
2type ParamsMetric struct {
3 // 记录热点参数值最后添加令牌的时间
4 RuleTimeCounter cache.ConcurrentCounterCache
5 // 记录热点热点参数值对应的令牌个数
6 RuleTokenCounter cache.ConcurrentCounterCache
7 // 记录实时热点参数值对应的并发个数
8 ConcurrencyCounter cache.ConcurrentCounterCache
9}
4.3 流量控制
下面重点介绍热点参数流控是如何利用LRU统计结构实现的流量计算以及流量的控制。
4.3.1 并发超过阈值-直接拒绝
并发超过阈值直接拒绝的流程比较简单,只需要用到统计结构(ParamsMetric)中的ConcurrencyCounter来记录热点参数值的并发数量即可,如下:
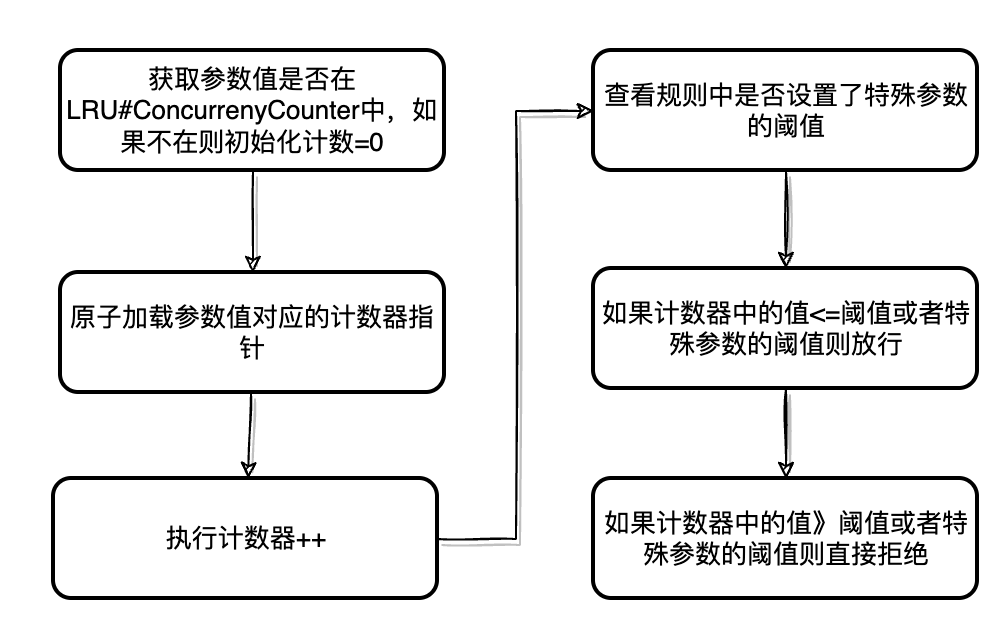
并发流控行为对应的代码实现:
1func (c *baseTrafficShapingController) performCheckingForConcurrencyMetric(arg interface{}) *base.TokenResult {
2 specificItem := c.specificItems
3 initConcurrency := int64(0)
4 concurrencyPtr := c.metric.ConcurrencyCounter.AddIfAbsent(arg, &initConcurrency)
5 if concurrencyPtr == nil {
6 // First to access this arg
7 return nil
8 }
9 concurrency := atomic.LoadInt64(concurrencyPtr)
10 concurrency++
11 if specificConcurrency, existed := specificItem[arg]; existed {
12 if concurrency <= specificConcurrency {
13 return nil
14 }
15 msg := fmt.Sprintf("hotspot specific concurrency check blocked, arg: %v", arg)
16 return base.NewTokenResultBlockedWithCause(base.BlockTypeHotSpotParamFlow, msg, c.BoundRule(), concurrency)
17 }
18 threshold := c.threshold
19 if concurrency <= threshold {
20 return nil
21 }
22 msg := fmt.Sprintf("hotspot concurrency check blocked, arg: %v", arg)
23 return base.NewTokenResultBlockedWithCause(base.BlockTypeHotSpotParamFlow, msg, c.BoundRule(), concurrency)
24}
4.3.2 QPS超过阈值-直接拒绝
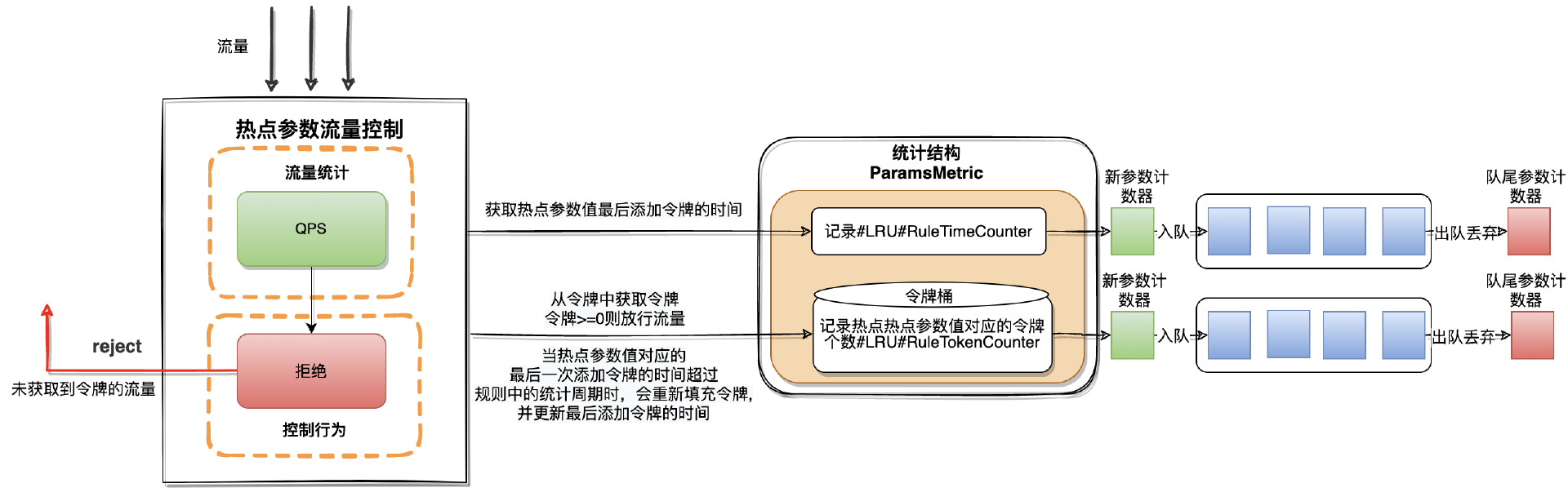
在QPS超过阈值直接拒绝的流控行为中会用到统计结构中的RuleTImeCounter和RuleTokenCounter,分别是记录热点参数值最后添加令牌的时间和热点参数值对应的令牌个数(令牌桶)。RuleTImeCounter和RuleTokenCounter都是利用LRU实现。
详细流程如下:
-
当流量请求经过时首先会获取参数对应的最后一次添加令牌的时间
-
如果没有获取到最后添加令牌的时间则有两种情况:
-
这个参数是第一次请求,需要为这个参数初始化令牌桶以及添加令牌的时间(对桶中的令牌计数器设置为流控规则中的阈值,添加令牌的时间设置为当前时间)
-
这个参数不是第一次请求并且不是热点数据,因为LRU算法的特性之前将它从队列中移除了,这种情况也同样需要初始化令牌桶以及添加令牌的时间
-
如果获取到最后添加令牌的时间会根据当前时间与最后一次添加令牌的时间进行计算时间差
-
如果计算结果>流控规则中的统计时长(DurationInSec)则需要重置令牌桶和添加令牌的时间
-
如果计算结果<=流控规则中的统计时长(DurationInSec)则从令牌桶中扣减令牌
-
如果扣减后令牌桶中的令牌个数>0则放行流量
-
如果扣减后令牌桶中的令牌个数<=0则直接拒绝当前流量
相关代码在hotspot模块下的traffic_shaping.go#rejectTrafficShapingController.PerformChecking()中,由于内容较长这里就不过展示了。
4.3.3 QPS超过阈值-匀速排队
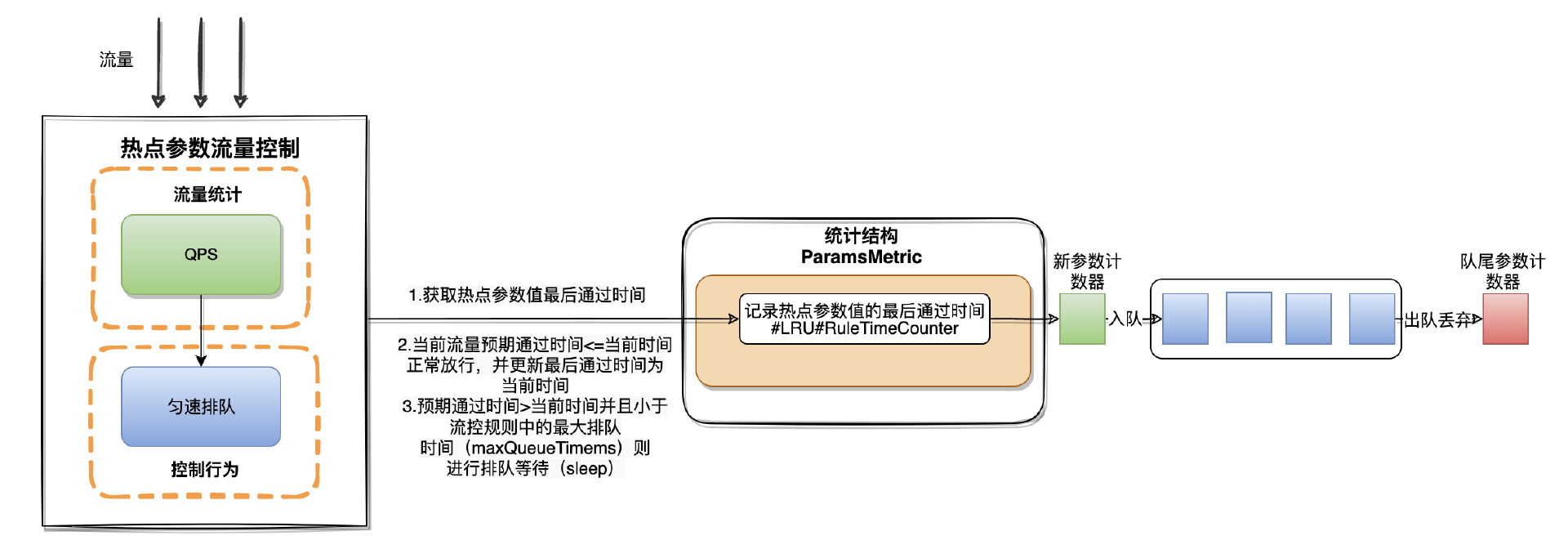
在QPS超过阈值匀速排队的流控行为中会用到统计结构中的RuleTImeCounter,与QPS直接拒绝的流控行为实现不同的是,在匀速排队场景下只使用了RuleTImeCounter,利用RuleTImeCounter记录热点参数值对应的最后通过时间。
匀速排队里有个很重要的概念就是流量的预期通过时间(漏桶算法)。 流量预期通过时间=流控周期(durationInSec)/ 限流阈值(Threshold)+ 当前热点参数值最后的通过时间
详细流程如下:
-
首先当流量请求经过时会到统计结构(ParamsMetric)中的RuleTimeCounter(LRU)中获取当前参数值最后一次通过的时间
-
如果当前流量预期通过的时间<=当前时间则直接更新最后通过时间为当前时间并放行流量
-
如果当前流量预期通过时间>当前时间,则需要计算两个时间的差值,利用差值和流控规则中最大排队时间(MaxQueueingTImeMs)进行比对
-
如果差值<最大排队时间说明当前流量需要进行排队等待
-
如果差值>=最大排队时间说明当前流量不能进行排队等待需要被拒绝
相关代码在hotspot模块下的traffic_shaping.go#throttlingTrafficShapingController.PerformChecking()中,由于内容较长这里就不过展示了。
5. 总结
热点参数流控支持:并发和QPS两种维度进行控制,控制的手段分为:直接拒绝和匀速排队。
热点参数流控更适合细粒度的流控场景,例如以商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制,或者以用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制。
热点参数流控底层并没有使用滑动时间窗口而是使用LRU作为统计结构,利用LRU的缓存淘汰特性,节省空间使用率,并利用令牌桶以及漏桶算法实现对流量的控制。
作者介绍
Github 账号:binbin0325,公众号:柠檬汁Code,Sentinel-Golang Committer 、ChaosBlade Committer 、 Nacos PMC 、Apache Dubbo-Go Committer。目前主要关注于混沌工程、中间件以及云原生方向。
